

行业解决方案查看所有行业解决方案
IDA 用于解决软件行业的关键问题。
发布时间:2022-10-10 11: 57: 50
经典的渗透测试需要评估各种弱点的技能,通常是处理常见的bug类。渗透测试期间很少利用内存损坏,原因是它们可能有风险(您不想使生产系统崩溃),而且可能很耗时(如果您开发/调整了漏洞)。使用公共脚本利用已知内存损坏漏洞的情况也相当罕见,因为供应商和用户都倾向于非常认真地对待他们的补丁。然而,这些类型的弱点可能使攻击者能够收集强大的原语,如远程命令执行或秘密窃取。

此外,在银行界,这类问题会引起巨大的骚动,这是常识,尤其是在没有补丁的情况下。尽管如此,在安全评估期间能够检测内存损坏,可以通过关闭易受攻击的服务来避免技术或经济灾难。
最后,让我们诚实地说:遗留软件几乎从未被审计过,因为只要有可能,主要部分都会退役。然而,其余部分几乎从未测试过。原因很简单:这类软件通常很难修补,导致用户避免在多个漏洞评估中浪费时间。通常情况下,第一次审计据称将查明最明显的弱点。只要检测到不会导致崩溃的内存损坏错误,几乎肯定不会被利用。
因此,我建议您遵循我对CVE-2019-4599的分析。这是我在经典渗透测试评估期间必须穿过的路径。起初我没想到会有这样的惊喜。
目标
IBM Sterling PeSIT FTP服务是一个完整交易环境的一部分,旨在同步大型金融实体之间的文件,以便跟踪(例如)外国银行的现金提取。这一原理被称为远程学习。
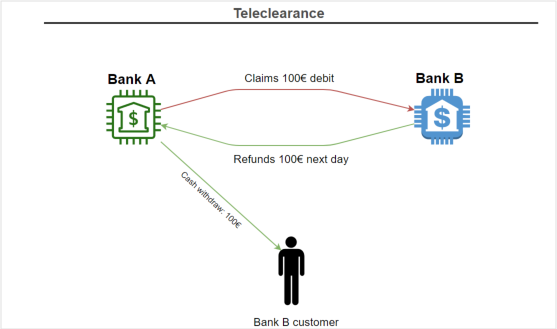
当然,这些文件的使用-以及它们的内容-可能会有所不同,但它们最终都是使用某种交换协议传输的。虽然国际标准建议使用SWIFT,但自20世纪80年代以来,法国银行一直在使用名为PeSIT的协议。
此外,Connect:Express软件套件中还包括FTP服务器。在两个法国组织之间无法建立PeSIT链路的情况下,它被用作回退协议。
因此,以下是攻击FTP服务器的要点:。
当被银行使用时,它在互联网上监听与其他银行实体的通信,尽管银行通常会将服务定位在IPSEC隧道后面。FTP协议本身是最著名的协议之一,其部分在几个RFC中进行了描述,更重要的是,渗透测试在开发编写阶段更具挑战性!
第二点并不真正相关,因为FTP协议的实现似乎没有遵循对利用漏洞至关重要的规范(RFC 959 p.30/31)。
静态分析
由于二进制文件是封闭源代码的,所以让我们从分解它开始。值得庆幸的是,二进制代码没有被剥离,大多数函数都以法语或法语/英语混合标记。查看main()函数,我们可以看到使用getopt()处理本地参数和标志,如下图所示:
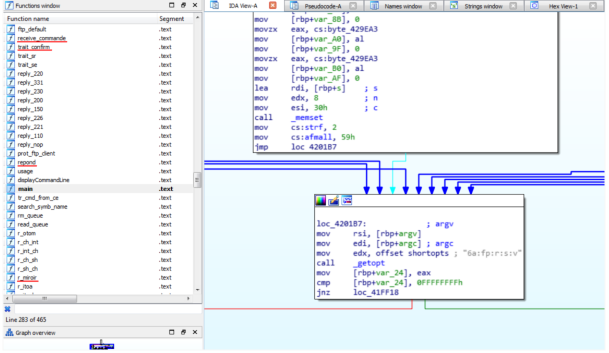
与任何典型的服务器一样,二进制文件从监听传入的TCP连接开始。一旦从远程对等点建立了连接,进程将获得fork(),receive_commande()处理客户端发送的TCP负载。即,我们的主要(远程)入口点:
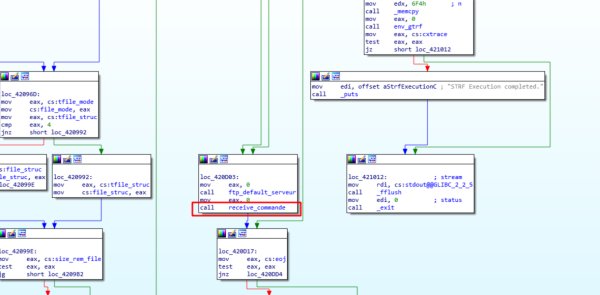
receive_commande()基本上调用两个函数:
●TCP_RECV():调用recv()
●analyse_commande():将FTP命令分派给适当的处理程序
我们先来分析一下TCP_RECV().这是一个简化版本:
void*TCP_RECV(int mode)
{
int fd;
int cur;
if(mode==2){
//load"more data"(e.g.partial file upload)
cur=lit_parm->buf_lg;
fd=sock_dtp;
}else{
[0]cur=0;
fd=sock_dcp;//incomming connection socket
}
[1]lit_parm->buf_lg=recv(fd,&lit_parm->buf[cur],lit_parm->max_len-cur,0);
if(lit_parm->buf_lg>0){
if(mode==1){
if(strf==2){
[2]lit_parm->buf_lg-=2;
}else{
//...
}
}else{
//...
}
}
//...
}
换句话说,它填充了以下struct lit_parm_t结构:
struct lit_parm_t{
char*buf;//pointer to user supplied data
int buf_lg;//length returned by recv()minus 2
//...
int max_len;//max buffer length
}
尤其是,lit_parm->buf保存从客户端读取的全部内容recv()[1],其中cur==0([0]).
人们可能会注意到[2]。是的lit_parm->buf_lg减2。老实说,我不知道为什么这个语句存在,但它实际上导致了一个错误(稍后会详细介绍)。
lit_parm本身是一个全局变量,指向在init()(在启动之前调用fork()):
void init()
{
//...
input_net=malloc(130976);
//...
lit_parm=calloc(1uLL,32uLL);
lit_parm->buf=input_net;
lit_parm->buf_lg=130976;
lit_parm->max_len=130976;
//...
}
反过来,input_net也是指向堆的全局变量。有人可能会注意到,“130976”看起来像是缓冲区的MAX_INPUT_SIZE。
一旦接收到数据TCP_RECV(),receive_commande()调用analyse_commande()这是主要的命令调度。analyse_commande()区分两组命令:
●预认证:HELP、STAT、USER/PASS、ALLO
●身份验证后:所有其他命令
从攻击面的角度来看,我们要么需要在认证前命令中找到漏洞,要么需要在认证后绕过,然后在认证后命令中找到漏洞。在后一种情况下,我们需要“两个漏洞”。这看起来更像是“工作”,并且具有预授权错误更性感!
在粗略查看了不同的pre-auth命令之后,重点已经放在了ALLO命令上。
ALLO command handler的ALLO命令(用于ALLOcate)是可以在预认证模式下它用于分配足够的空间在文件上传之前通常,下一个命令例如应该是STOR。
正如RFC959代表的,预期的语法是:
ALLO [R]
一旦收到数据TCP_RECV()(因此两者lit_parm->buf和lit_parm->buf_lg已填充),ALLO命令处理程序(调用自analyze_commande())尝试执行以下操作:
1.查找的长度(按字符)
2.如果实际上是一个数字,则将用户提供的数据(即)复制到rem_file缓冲
让我们检查一下实现:
int i;
//find the number of characters of""(stop at first space or ends of data)
[0]for(i=0;lit_parm->buf_lg-5>i&&lit_parm->buf[5+i]!='';++i)
{
}
[1]if(verif_num(i,(*lit_parm->buf+5))){
if(lit_parm->buf_lg-5
copy_len=i-1;
else
copy_len=i;
[2]memcpy(rem_file,(*lit_parm->buf+5),copy_len);
rem_file[copy_len]=0;
//...
为了使事情更简单,让我们调用位于过去5个字节的字符串lit_parm->buf:有效载荷。
所以,变量i设置为PAYLOAD的[0]。然后,检查PAYLOAD仅由数字组成verif_num()在[1]中。最后,缓冲区rem_file填充有PAYLOAD大小copy_len在[2]中。
人们可能会立即注意到在测试期间没有“长度检查”memcpy()在[2]中。它充满了大小的用户控制数据(PAYLOAD)copy_len进入rem_file.全局变量rem_file本身存储在.bss作为256字节的字符数组。
换句话说,传递以下命令会导致.bss中的缓冲区溢出:
ALLO 111...<252 times>...111111
^start overflowing on the next variable in the.bss
此时,对PAYLOAD是它只能包含由verif_num().则后者返回true PAYLOAD仅由数字组成,i为零。
这可能看起来像这里的“大赢”,但“大赢”不等于“速赢”:-)。
事实上,仅限于“仅数字”字符会导致更难的利用。在下一节中,我们将展示如何绕过这个限制并溢出rem_file具有几乎任意数据的缓冲区。
绕过verif_num()
在上一节中,我们看到我们可以触发.bss上的缓冲区溢出,但它有一个限制:我们的有效负载仅限于数字字符。
实施
首先,让我们看看verif_num()实现:
bool verif_num(int ctr,char*test_char)
{
int i;
for(i=0;i);++i)
{
}
return i==ctr;
}
为了通过检查,字符串test_char必须由数字字符组成,最多为ctr字符。
此外,如果ctr设置为零,verif_num()将始终返回true。
回到ALLO处理程序代码,我们看到verif_num()的ctr参数是使用这里计算的i变量调用的:
for(i=0;lit_parm->buf_lg-5>i&&lit_parm->buf[5+i]!='';++i)
{
}
在这里被称为:
if(verif_num(i,(lit_parm->buf+5))){
...
}
并在此调用:基本测试用例
好,让我们用一些实际数据来分析这一部分。以下是我们的测试用例:
|#case|lit_parm->buf|lit_parm->buf_lg|i|verif_num()|copy_len|comment|
|-----|-------------|----------------|-|-----------|--------|-----------------------|
|0|'ALLO'|5|0|true|0|with one space|
|1|'ALLO a'|6|0|false|n/a||
|2|'ALLO 1'|7|0|true|0|two spaces before digit|
|3|'ALLO a'|7|0|true|0|two spaces before char|
|4|'ALLO 1'|6|1|true|1||
|5|'ALLO 1'|7|1|true|1|one space after|
|6|'ALLO 12'|7|2|true|2||
正如我们在#0、#1、#4、#5和#6的情况下看到的,verif_num()表现如预期,以及i值设置正确。反过来,copy_len等于i.
但是,查看案例#2和#3,在ALLO命令之后插入两个空格,我们看到i总是设置为零,因此verif_num()也返回真!
也就是说,我们达到以下代码:
[0]if(lit_parm->buf_lg-5
copy_len=i-1;//<----unreachable code?!
else
copy_len=i;
[1]memcpy(rem_file,lit_parm->buf+5,copy_len);
回到案例#3,我们看到我们的有效载荷可以是ALLOa或者ALLOaaaaaaa...(两个空格)。换句话说,通过使用“两个空格技巧”,我们可以将一些任意数据放入PAYLOAD。
在那些情况下,i也设置为零,即copy_len设置为零!不能这样调用0字节的溢出!
相反,回顾上一段代码中的[0]行,这个条件似乎永远不会为真,因为lit_parm->buf_lg最小值为5.或...是吗?
重新考虑测试用例
还记得之前公开的TCP_RECV()吗?是的,在调用recv()之后出现了一条“奇怪的线”:
lit_parm->buf_lg=recv(fd,&lit_parm->buf[cur],lit_parm->max_len-cur,0);
//...
lit_parm->buf_lg-=2;//<----what the hell?!
所以是的,我们之前的测试用例是错误的,让我们重写它们!
回到计算i,我们看到如果lit_parm->buf_lg小于5,然后i将始终设置为零(它不会在for环形)。因此,verif_num()也总是返回true!
|#case|lit_parm->buf|lit_parm->buf_lg|i|verif_num()|copy_len|comment|
|-----|-------------|----------------|-|-----------|----------|-----------------------|
|0|'ALLO'|3|0|true|0xffffffff|with one space|
|1|'ALLO a'|4|0|true|0xffffffff||
|2|'ALLO 1'|5|0|true|0xffffffff|two spaces before digit|
|3|'ALLO a'|5|0|true|0xffffffff|two spaces before char|
|4|'ALLO 1'|4|0|true|0xffffffff||
|5|'ALLO 1'|5|0|true|0|one space after|
|6|'ALLO 12'|5|0|true|0||
换句话说,如果我们的PAYLOAD的大小为零或一个字符(无论如何),copy_len设置为0xffffffff。
这是一个INT UNDERFLOW婴儿,会导致巨大的memcpy()在.bss!
我们可能会从中受益,但它引发了两个问题:
1.覆盖从开始的0xffffffff字节.bss肯定崩溃会使进程
2.我们可以实际控制数据(即PAYLOAD)并且不限于零或一个字节吗?
滥用未初始化内存
回到memcpy()在ALLO命令处理程序中调用,我们看到我们可以触发巨大的缓冲区溢出rem_file(位于.bss部分)。代码是:
memcpy(rem_file,lit_parm->buf+5,copy_len);
提醒一句,lit_parm->buf已设置且仅设置在recv(),即用户控制的数据:
lit_parm->buf_lg=recv(fd,&lit_parm->buf[cur],lit_parm->max_len-cur,0);
需要注意的一件事是lit_parm->buf(初始化于init()之前fork())永远不会在每个之间recv()称呼!让我们利用这种行为来溢出rem_file缓冲区任意数据。
基本上,利用策略变为:
1.call<5 bytes>:将数据设置在lit_parm->buf
2.调用ALLO<0或1个任意字节>:仅覆盖5或6个第一个字节lit_parm->buf并使缓冲区的其余部分保持不变。
当然,我们最多只能控制130971(130976-5)字节的数据。这是因为lit_parm->max_len限制。
查看进程的内存布局,这将覆盖整个.bss部分,然后点击NULL页面并引发segfault!
这是一个解决的问题!不过还有一个问题:如何利用巨大的溢出(0xffffffff字节)会引发segfault的事实?
处理巨大的溢出
通常,当缓冲区溢出错误覆盖了很大一部分连续(虚拟)内存时,很有可能引发页面错误(试图写入非映射内存和/或只读页面)。在这些情况下,内核向通常被终止的进程发出SIGSEGV信号。
然而,看着init()函数,我们看到设置了很多不同的信号处理程序:
puts("init:*****signals caught");
signal(1,1);
signal(2,sig_fin);
signal(3,sig_fin);
signal(4,sig_fin);
signal(5,1);
signal(6,sig_fin);
signal(8,sig_fin);
signal(7,sig_fin);
signal(11,sig_fin);//SIGSEGV
signal(31,sig_fin);
signal(13,1);
signal(14,1);
signal(15,sig_fin);
signal(20,1);
signal(17,sig_chld);
signal(21,1);
signal(22,1);
signal(29,1);
signal(10,sig_usr1);
signal(12,sig_usr2);
因此,二进制文件为SIGSEGV信号绑定了一个信号处理程序:sig_fin()。换句话说,如果我们的溢出在调用memcpy()期间引发SIGSEGV,执行流将重定向到sig_fin()。
原文地址:https://blog.lexfo.fr/pentesting-pesit-ftp.html
展开阅读全文
︾
专业销售为您服务

读者也喜欢这些内容:
怎么用IDA软件反汇编功能学习汇编指令 IDA反汇编功能如何进行多平台二进制分析
说到反汇编分析,很多人第一时间就会想到IDA。这款工具可以说是做逆向工程的“神器”,不管是学习汇编指令还是分析二进制文件,都非常给力。如果你是个初学者,刚接触反汇编,可能会对IDA的一些功能感到陌生,比如怎么用IDA软件反汇编功能学习汇编指令 IDA反汇编功能如何进行多平台二进制分析。别急,今天就带你一步步搞清楚。...
阅读全文 >
IDA静态分析怎么做?IDA静态分析需要多久?
在软件逆向工程与安全分析行业,IDA 因其强大的功能,已成为业内不可或缺的工具之一。尤其是在静态分析方面,IDA提供了一系列高效功能和技术,激励安全分析师和反向工程师全面了解目标软件的内部结构和逻辑。本文将详细讨论ida静态分析怎么做,ida静态分析需要多久,帮助其更有效的运用IDA开展静态分析,掌握静态分析与动态变化实践应用的差别和联系。...
阅读全文 >
IDA怎么修改字符串内容?IDA修改后怎么保存?
在软件开发和逆向工程领域,IDA Pro是一种极其强悍的工具,广泛用于程序剖析、调试和修改。它不仅支持多种处理器架构,还提供了大量的作用,以适应高档讲解的必须。本文将围绕ida怎么修改字符串内容,ida修改后怎么保存这一主题,详细描述怎样在IDA中更改字符串内容,及其修改后的存放方式。此外,我们还将探讨IDA转变的应用场景,帮助读者更深入地了解IDA的实际应用价值。...
阅读全文 >
怎么把汇编语言转化为c语言 怎么把hex文件转换成c文件
在计算机编程的广阔领域中,理解不同编程语言之间的转换机制是一项重要的技术挑战。特别是在涉及到汇编语言和C语言这两种在软件开发中极为重要的语言时,了解它们之间的转化过程显得尤为关键。...
阅读全文 >
 汽车安全
汽车安全  金融保险
金融保险  游戏开发
游戏开发  网络安全与防护
网络安全与防护  工业4.0应用升级产业
工业4.0应用升级产业  渗透测试
渗透测试  教育
教育  知识产权
知识产权 司法鉴定
司法鉴定 